Mc-Kmeans: A highly efficient multi-core k-means algorithm for clustering extremely large datasets.
Usage
The software requires the Java runtime environment (JRE) version 1.6, which can be downloaded from java.sun.com. Hint for Mac OSX 10.5 users: You can change your default JVM version using the Java Preferences Application under /Applications/Utilities/Java Preferences.app.
After downloading the McKmeans GUI version it is started by double-clicking McKmeans.jar or via the following command on a terminal:
java -jar McKmeans.jar
If large input files are processed, the Java virtual machine (JVM) needs more memory (e.g. 1 GB). The command then is:
java -Xmx1g -jar McKmeans.jar
Alternatively, windows users can download a start script McKmeans.bat and start the software by a double-click on this file.
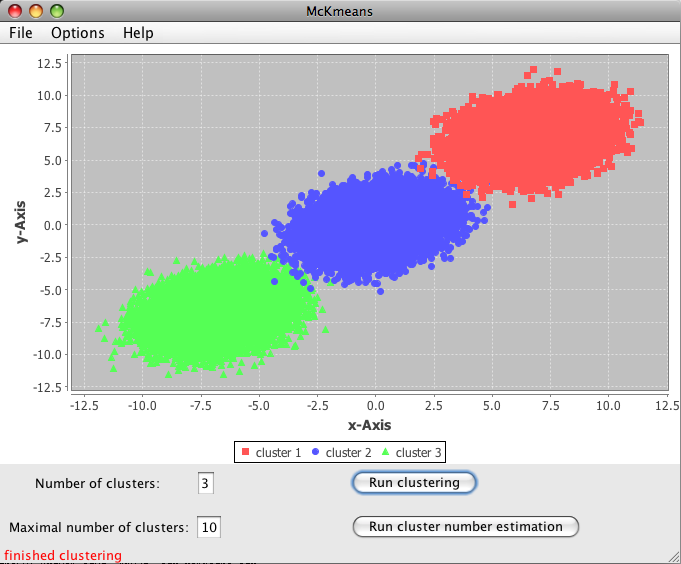
To start clustering, you have to load a data set via File->Load. Example data sets are provided below. The first two features of the data set are displayed in the plotting region. You can change the features to plot via the Options menu.
Then you can choose the number of clusters. The clustering starts by clicking on the run clustering button. The cluster analysis may take a while, e.g. 25 minutes for clustering our example data set containing 1000000 data points into 20 clusters on a dual-quad core computer. The resulting clustering is displayed in the plotting area. Additionally, the assignment vector can be saved via the Save menu. This text output shows the cluster number for each data point in the ordering of the original data set.
The following picture shows a clustering of an extremely large data set (100000 data points, 100 features):
Cluster number estimation
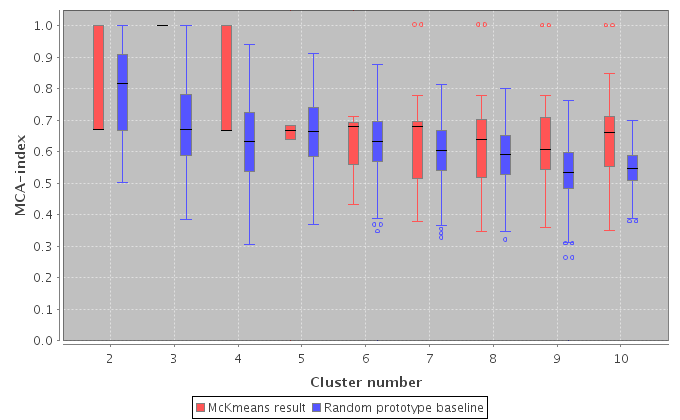
Cluster number estimation can be performed by clicking on the cluster number estimation button. The parameters for the cluster number estimation can be changed via the Options menu. Calculating the cluster number estimation may take several minutes. The result is shown as a boxplot chart (displaying the median and interquartile range). It can be exported to a svg file via the Export menu. The most stable clustering (greatest difference between mean cluster result and mean random clustering) is also shown on the main program frame.
The following picture shows a result of the cluster number estimation.
Alternative usage -- The script version
The script version requires Clojure and Java 1.5 or higher. Clojure can be downloaded from clojure.org.
Install JRE if it is not available on your system.
Hint: For larger data sets the value of the parameter -Xmx must be increased to reserve the appropriate amount of memory for Java.
Load the parallel k-means script by typing (load-file "McKmeans.clj").
After loading the script, a data set must be loaded. A simple example is available in the Download Section.
The function to load and define the data set is (def dataset (load-tab-file "cluster_example.tab")).
The number of clusters k and the maximum number of iterations can be set via (def k 20) and (def maxiter 100).
K-means is started by calling the function (kmeans). The runtime can be seen by calling (time (kmeans)).
Results of the clustering are available with the function (read-out).
The GUI version can be downloaded from this link:
McKmeans.jar.
The script version can be downloaded from this link:
McKmeans.clj.
Data sets
The data format is a tab-delimited text file without column or row names. Each row contains a sample, each column contains a feature.
The following examples are available for download:
A script for generating artificial microarray experiment data can be downloaded here.
Additionally, the microarray data set cited in the paper is available from this link. You can use this R-script to transform the data into the input format of McKmeans.